
Part 2: Feature Geometry, Representation Limits, and Baseline Models
Why better representations outperform better algorithms in sentiment analysis

In Part 1, we framed sentiment analysis as a system.
Now we examine what that system actually looks like numerically.
Because once text becomes vectors, structure — or lack of it — becomes visible.
TF-IDF: Not a Solution, but a Necessary Correction
Switching from raw counts to TF-IDF does exactly what it should:
event-specific words lose dominance
rarer, informative terms gain weight
This doesn’t “solve” sentiment.
It simply removes obvious distortions.
That distinction matters.
TF-IDF doesn’t add signal — it redistributes attention.

Visualizing the Feature Space (and Facing Reality)
We apply t-SNE to TF-IDF embeddings.

The result is instructive:
neutral tweets cluster weakly
positive and negative tweets overlap heavily
no clean separation emerges
This visualization tells us something models won’t:
The dataset itself is structurally ambiguous.
No amount of modeling will create clean decision boundaries where none exist.
This is a hard ceiling — and recognizing it saves months of wasted effort.
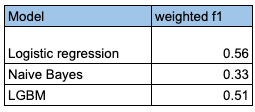
Baseline Models Without Cleaning
Before complex preprocessing, we test simple learners:
Logistic Regression
Naive Bayes
LightGBM
Results are consistent:
Naive Bayes underperforms significantly
Logistic Regression is strong and stable
LightGBM performs best
This reinforces a recurring pattern in applied NLP:
Model complexity matters less than representation alignment.
Turning Features into a System
To stabilize performance, we:
combine train and test for TF-IDF statistics
reduce dimensionality with Truncated SVD
integrate structured features:
retweet count
tweet length
encoded author identity
This produces a robust baseline with ~42 weighted F1.
Importantly:
performance is stable
variance across runs is low
behavior is interpretable
At this point, many pipelines stop.
That’s a mistake.
What This Part Established
TF-IDF fixes distortions, not ambiguity
Visualization reveals performance ceilings early
Baselines should be strong before optimization
Representation dominates algorithm choice
In Part 3, we push the system further — and learn where improvement genuinely ends.
Note: refer to my detailed medium article for expanded version of this and accessing the code etc. Link