
Part 1: Framing Sentiment Analysis as a Systems Problem (Not a Modeling Problem)
Why most sentiment analysis pipelines fail before training even begins

Most sentiment analysis tutorials start with models.
Logistic regression vs LSTM.
TF-IDF vs embeddings.
Accuracy comparisons and leaderboard scores.
That’s already the wrong starting point.
If you’ve worked with real-world sentiment data, you’ve likely seen the same failure modes repeat:
Models plateau early
Small feature changes swing results wildly
Improvements don’t generalize out of sample
This isn’t because sentiment analysis is poorly understood.
It’s because sentiment analysis is rarely framed as a system-design problem.
In this series, we treat it as one.
Sentiment Analysis Is Not a Single Task
“Detect sentiment” sounds simple until you inspect the data.
In this dataset, we’re classifying tweets into:
positive
neutral
negative
But immediately, ambiguity appears:
Neutral tweets dominate the dataset
Language is noisy and sometimes incorrect
Many tweets are variations of the same event context
Before touching a model, we ask a more important question:
Where can real signal plausibly exist?
Class Imbalance and Why Accuracy Is Misleading
The dataset is moderately imbalanced:
~50% neutral
~25% positive
~25% negative
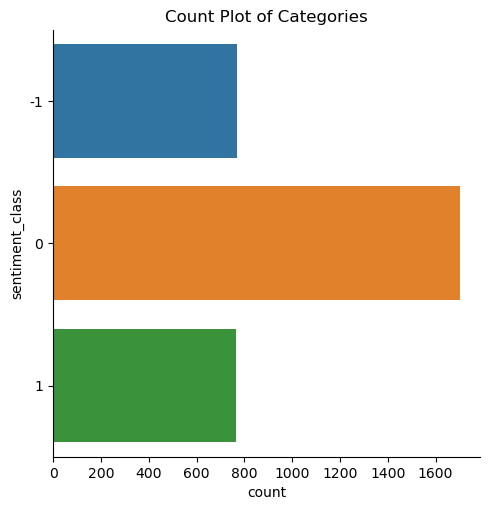
This immediately rules out accuracy as a useful metric.
Accuracy rewards predicting “neutral” often — even if the model is useless.
Instead, we commit to weighted F1, which:
penalizes poor minority-class performance
reflects real-world cost asymmetry
forces the system to care about all labels
This decision alone prevents a large class of silent failures.
Metadata Isn’t Optional — It’s Signal
Author Identity
At first glance, author ID seems irrelevant.
But aggregation reveals a pattern:
authors who tweet neutrally tend to remain neutral
sentiment behavior clusters by user
This is behavioral leakage — and ignoring it discards usable signal.
Retweet Count
Retweet count is noisy and inconsistent.
Its relationship with sentiment isn’t obvious.
But uncertainty doesn’t mean uselessness.
In systems work, ambiguous features are retained until proven harmful — not discarded prematurely.
Language Field
Despite noise, nearly all tweets are English.
This feature adds entropy without information.
It is removed.
Tweet Length
Length distributions overlap heavily across classes.
Still, subtle differences exist — especially between neutral and negative tweets.
Weak signals matter when aggregated.
First Contact with Text: Why Frequency Lies
We begin with CountVectorizer and word clouds — not for modeling, but for inspection.
The result is predictable:
words like happy, mother, day dominate
context overwhelms sentiment

This confirms a core principle:
Raw frequency reflects topic, not sentiment.
This sets the stage for representation learning — which we tackle next.
What This Part Established
Sentiment analysis failures start before modeling
Metrics encode assumptions — choose them deliberately
Metadata often matters more than intuition suggests
Representation quality sets performance ceilings
In Part 2, we move from intuition to geometry — and examine what sentiment looks like once converted into vectors.
Note: refer to my detailed medium article for expanded version of this and accessing the code etc. Link