
Building MLOps Pipelines That Scale: Lessons from Production Deployments
A practical roadmap to building resilient, automated MLOps pipelines that keep your models reliable long after the demo magic fades.

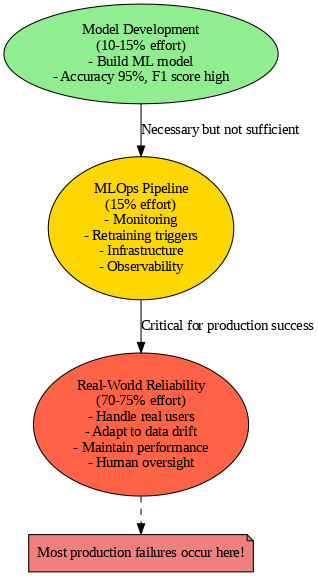
Hidden Complexity Behind ML Models in Production
Building a machine learning model that achieves 95% accuracy in testing feels amazing. Your F1 score looks great, everyone’s excited, and you confidently deploy your model to production on Monday, expecting it to perform equally well for real users.
But by Wednesday, your production ML system starts falling apart. Predictions look strange and don’t make sense. Model inference speed degrades daily. The situation keeps getting worse. This production ML failure scenario happens constantly — and most teams don’t see it coming.
Most data scientists think building the machine learning model is the hardest part: data cleaning, feature engineering, algorithm selection. It feels like once that’s done, you’re finished. But that’s only 10–15% of production ML work.
The othe`
Why MLOps is Needed
Machine learning changed the way companies build software in a big way. Unlike regular software, which follows fixed rules, machine learning models depend on data — and data is always changing. So, a model that worked great yesterday might suddenly start making bad predictions today, without any clear error message. Because of this, companies needed a new approach called MLOps, which stands for Machine Learning, Development, and Operations.
MLOps is like traditional software development but with some key extra challenges. You need automated pipelines that take raw data and use it to train models, which then make live predictions. But it’s not just about managing code — you also need version control for data and the models themselves. Continuous integration and deployment (CI/CD) processes have to be specially designed for ML systems. Plus, monitoring is crucial to catch model drift — a silent drop in performance — before users notice problems. Finally, good governance is needed so everything is trackable and reproducible.
What makes MLOps really different from traditional DevOps is how it handles the changing data and models. There’s data coming from many different sources, models have to be retrained regularly, and monitoring isn’t just about uptime but also about how accurate the model stays. And when you’re working at scale, building the system to grow smoothly isn’t just a nice-to-have — it has to be planned from the start.
An effective MLOps pipeline has several key parts that work together to keep machine learning systems healthy and scalable:
Data Ingestion and Validation: Ensures incoming data is clean, consistent, and ready for use.
Feature Store Management: Organizes and reuses features across different models to save time and improve consistency.
Model Training and Versioning: Automates the building of new models and tracks every version to maintain reproducibility.
Deployment Strategies: Safely rolls out new models to users using techniques like canary or blue-green deployments.
Monitoring and Feedback Loops: Continuously observes model performance and triggers retraining or adjustments when problems start.
Together, these components build pipelines that can handle real-world complexities and grow with your needs. Let’s elaborate on these in next section.
Core Components of a Scalable Pipeline
Data Ingestion and Validation
Reliable machine learning pipelines start with clean and consistent data. Industry practitioners often use tools like Great Expectations or TensorFlow Data Validation to automate data quality checks, detecting schema changes, missing values, or anomalous distributions early. Common metrics tracked include completeness, uniqueness, and range violations. The methodology involves setting up data contracts with producers to enforce expected formats and continuous validation during ingestion. Versioning raw datasets using tools like DVC or Delta Lake ensures reproducibility and traceability.
Feature Store Management
Centralized feature stores such as Feast, Tecton, or Snowflake are widely used to maintain reusable and versioned features. Features are treated as immutable data entities with metadata describing their update frequency, freshness, and lineage. Key metrics include feature freshness latency and feature usage frequency. Industry best practices include materializing computed features as batch views or streaming views, enforcing access controls, and leveraging feature seeds to bootstrap new projects without duplication. Documenting feature logic in code repositories alongside metadata fosters collaboration.
Model Training and Versioning
Automated model training pipelines leverage tools like MLflow, Kubeflow Pipelines, or Amazon SageMaker to orchestrate experiments and track hyperparameters, metrics, and artifacts. Model versioning is managed by registries such as MLflow Model Registry or SageMaker Model Registry, facilitating rollback and auditability. Key evaluation metrics include accuracy, F1 score, ROC-AUC, and loss functions depending on the problem type. Methodologies include continuous integration testing for models, validation on out-of-sample data, and A/B testing prior to deployment.
Deployment Strategies
Deployment patterns such as blue-green, canary, and shadow deployments are implemented using platforms like Kubernetes, Istio, or AWS Elastic Beanstalk. These enable routing a portion of live traffic to new models while monitoring their behavior without impacting end users. Metrics tracked include inference latency, error rates, and user engagement metrics. Methodologies emphasize gradual rollouts, automatic rollback triggers on degradation detection, and infrastructure as code (IaC) using Terraform or CloudFormation to ensure reproducible deployments.
Monitoring and Feedback Loops
Monitoring is done with tools like Prometheus, Grafana, or Evidently AI to collect real-time metrics on model accuracy, prediction distribution, data drift, and latency. Alerts are set up to trigger on threshold breaches. Organizations follow methodologies of data and concept drift detection, root cause analysis, and automated retraining pipelines. Incorporating user feedback and periodically validating models with fresh labeled data ensures sustained performance. Some teams integrate active learning loops to label uncertain predictions and improve over time.4. Lessons from Production Deployments
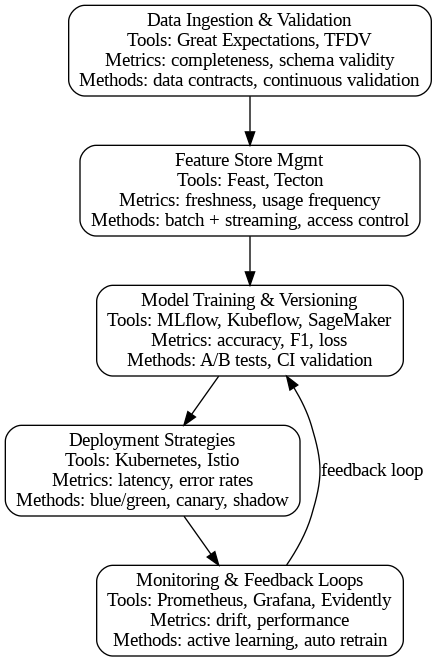
Six Industry-Standard Tools That Make MLOps Actually Work
Great Expectations (Data Ingestion & Validation)
Great Expectations is a leading open-source Python library for automated data validation that helps teams define, document, and enforce data quality standards across pipelines.
Automates schema checks, uniqueness constraints, and value range validations during data ingestion
Catches issues like missing values or distribution anomalies before they propagate downstream
FinTrust Bank reduced error rates from 5% to 0.25% using Great Expectations in their financial reporting pipeline, significantly lowering regulatory penalty risks
Microsoft Fabric users leverage it within notebooks to validate datasets programmatically
Generates comprehensive Data Docs providing real-time visibility into validation results
Enables teams to track data quality over time and take corrective actions before issues reach production systems
MLflow (Model Training & Versioning)
MLflow is an open-source platform that manages the complete machine learning lifecycle, providing experiment tracking, model versioning, and deployment capabilities.
Tracks parameters, metrics, code versions, and artifacts for every experiment run
Enables systematic comparison of hundreds of hyperparameter configurations
MLflow Model Registry manages model versions with associated datasets and code commits
Databricks customers use MLflow to monitor GenAI applications in production, tracking operational metrics like latency and token consumption
Supports local experiment organization for individual data scientists and centralized tracking servers for teams
Lightweight tracing SDK enables faster deployments in containers and serverless environments
Kubernetes (Deployment Strategies)
Kubernetes has become the de facto standard for deploying and scaling machine learning models in production with automated orchestration and self-healing.
Orchestrates containerized models with automated load balancing and scaling capabilities
Integrates with KServe and Seldon-Core to implement blue-green, canary, and shadow deployment strategies
MLflow models are containerized and deployed via kubectl commands with automatic traffic-based scaling
Teams test deployments locally with Kind or Minikube before moving to production
Cloud-based clusters use LoadBalancers to expose inference endpoints
Companies like Uber, Lyft, GoJek, Spotify, and PayPal use Kubeflow on Kubernetes at massive scale
Persistent volume claims (PVCs) enable efficient model storage and sharing across pods
Feast (Feature Store Management)
Feast is an open-source feature store providing centralized management of reusable, versioned features for both training and serving, solving training-serving skew problems.
Centralizes features across multiple data sources — data warehouses like BigQuery, Redshift, or Snowflake for offline stores
Uses Redis, DynamoDB, or Cloud Bigtable as online stores for low-latency feature retrieval during inference
E-commerce companies combine user data with real-time web traffic to create features like “product page views in the last hour” for recommendations
Google Cloud customers use Feast to materialize features incrementally with
feast materialize-incrementalSupports multiple environments (staging and production) with separate offline and online stores
Bytewax materialization engine processes multiple data ranges concurrently to handle large volumes efficiently
Enables horizontal scaling of feature servers to accommodate traffic spikes
Prometheus & Grafana (Monitoring & Feedback Loops)
Prometheus and Grafana form a powerful monitoring stack for tracking ML model performance, data drift, and infrastructure health in production.
Prometheus collects time-series metrics by scraping HTTP endpoints from ML applications
Tracks prediction latency, request throughput, error rates, CPU/memory usage, and custom metrics like prediction distribution
Teams instrument FastAPI prediction services with Prometheus client libraries to expose counters, histograms, and gauges
Grafana creates customizable dashboards with real-time visualizations and trend analysis
Alerts trigger when metrics exceed thresholds — like latency spikes or accuracy drops — with notifications via email, Slack, or Discord
Evidently AI integrates specialized ML monitoring capabilities through Prometheus endpoints
Monitors both operational metrics (resource usage, response times) and ML-specific metrics (data drift, feature distribution changes)
Scales naturally with Kubernetes, scraping metrics from multiple model pods with unified visibility
Kubeflow Pipelines (End-to-End Workflow Orchestration)
Kubeflow Pipelines serves as the orchestration backbone for automated, reproducible ML workflows with explicit dependencies and data flow.
Automates the entire ML lifecycle — data loading, preprocessing, feature engineering, training, validation, and deployment
CERN and research institutions use KFP to track thousands of training runs with experiment management
Companies like Uber and Spotify deploy and maintain models across distributed Kubernetes clusters
Enables data scientists to manually experiment initially, then codify optimized workflows into automated pipelines
Automates model propagation — once retrained and validated, changes roll out automatically to all client services
GenAI teams use Kubeflow for synthetic data generation with GANs, RAG data transformation using Spark operators, and LLM fine-tuning
Integrates with Feast feature stores for efficient feature serving
Supports hyperparameter tuning with Katib and model serving frameworks like KServe for complete end-to-end MLOps
Future of Scalable MLOps
What’s Changing in Machine Learning Operations
Machine learning is starting to move in new directions, and MLOps is changing along with it. Right now, we’re seeing big companies deal with large language models (LLMs) like ChatGPT, and these work really differently from regular machine learning models. They have different problems to solve — like managing how much each prediction costs, or figuring out how much text context the model can handle. At the same time, privacy laws are getting stricter everywhere. Companies can’t just collect all their data in one place anymore. So federated training is becoming important — this means training models where the data stays spread out across different locations, and the model gets better without anyone moving sensitive information around.
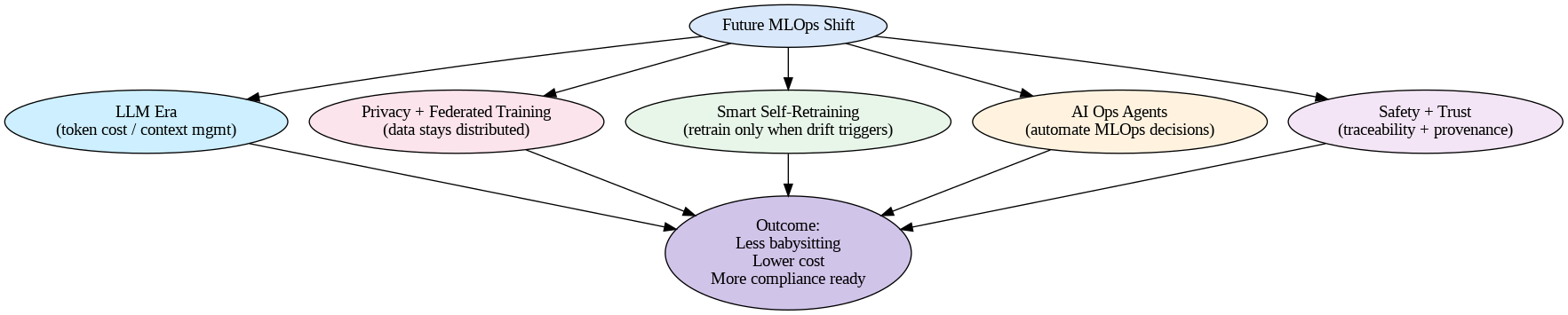
The Real Changes Coming to MLOps
Here’s what’s going to make the biggest difference in how teams build MLOps systems:
Models That Retrain Themselves Smartly — Instead of retraining models on a fixed schedule (like every Monday), smarter systems will watch for when things actually go wrong and only retrain when needed. This saves a lot of money and computing power
Robots That Manage Your MLOps — AI agents will start handling repetitive work like spotting when models get worse, figuring out what to do about it, and automatically starting the retraining process. Teams won’t have to watch everything manually anymore
Combining Safety with Monitoring — Companies are realizing they need to track not just whether models are accurate, but also where the data came from, who used each feature, and why the model made each decision. This is becoming required for legal reasons and for building trust.
How Companies Will Work Differently
Next-generation MLOps systems are shifting from manual monitoring to autonomous, self-healing automation. Teams won’t babysit models anymore — intelligent MLOps pipelines will automatically detect issues and trigger fixes. These systems embed privacy and AI governance from the start, not as add-ons.
The Real Benefits:
Lower costs through intelligent automation — only necessary ML operations execute
Better reliability — fewer production failures with autonomous issue detection
Faster compliance — built-in governance satisfies regulatory requirements like the EU AI Act
Reduced overhead — fewer MLOps engineers needed for day-to-day monitoring
Companies building autonomous MLOps architectures today gain competitive advantage: less operational firefighting, better system stability, and readiness for future AI regulations before mandates arrive.
Conclusion: Building MLOps That Works
Building a machine learning pipeline that actually works in production isn’t complicated if you focus on three things: scalability, automation, and maintainability. Scalability means your system can handle ten times more data or users without falling apart. Automation means you’re not manually retraining models or checking if things are working — the system does that for you. And maintainability means other people on your team can understand what’s happening and fix problems without waiting for one expert to be available.
The good news is that tools like Great Expectations, MLflow, Kubernetes, and Feast make this way easier than it used to be. You don’t need to build everything from scratch. But here’s the thing — tools alone aren’t enough.
You need to think about your pipeline as a system, not just individual pieces.
Here’s what you should do right now: sit down and look at your current ML pipeline honestly. Ask yourself these questions: Are you manually running training jobs? Do you have monitoring to catch when models break? Can someone else understand how your data flows through the system? Are you scaling linearly with your data, or does everything slow down? If you answered “no” to any of these, you’ve found your scalability gaps. That’s where you start. Pick one gap, choose the right tool to fix it, and then move to the next one. That’s how you build MLOps that scales.
Thanks for reading Indie's Substack! Subscribe for free to receive new posts and support my work.